

Pod Shedulling
공식 문서: https://kubernetes.io/ko/docs/concepts/scheduling-eviction/assign-pod-node/, https://kubernetes.io/ko/docs/concepts/scheduling-eviction/kube-scheduler/
쿠버네티스에서 스케줄링 은 Kubelet이 파드를 실행할 수 있도록 파드가 노드에 적합한지 확인하는 것을 말한다.
스케줄러는 노드가 할당되지 않은 새로 생성된 파드를 감시한다. 스케줄러가 발견한 모든 파드에 대해 스케줄러는 해당 파드가 실행될 최상의 노드를 찾는 책임을 진다. 스케줄러는 아래 설명된 스케줄링 원칙을 고려하여 이 배치 결정을 하게 된다.
파드가 특정 노드에 배치되는 이유를 이해하려고 하거나 사용자 정의된 스케줄러를 직접 구현하려는 경우 이 페이지를 통해서 스케줄링에 대해 배울 수 있을 것이다.
nodeName
nodeName 은 가장 간단한 형태의 노트 선택 제약 조건이지만, 한계로 인해 일반적으로는 사용하지 않는다. nodeName 은 PodSpec의 필드이다. 만약 비어있지 않으면, 스케줄러는 파드를 무시하고 명명된 노드에서 실행 중인 kubelet이 파드를 실행하려고 한다. 따라서 만약 PodSpec에 nodeName 가 제공된 경우, 노드 선택을 위해 위의 방법보다 우선한다.
nodeName 을 사용해서 노드를 선택할 때의 몇 가지 제한은 다음과 같다.
- 만약 명명된 노드가 없으면, 파드가 실행되지 않고 따라서 자동으로 삭제될 수 있다.
- 만약 명명된 노드에 파드를 수용할 수 있는 리소스가 없는 경우 파드가 실패하고, 그 이유는 다음과 같이 표시된다. 예: OutOfmemory 또는 OutOfcpu.
- 클라우드 환경의 노드 이름은 항상 예측 가능하거나 안정적인 것은 아니다.
여기에 nodeName 필드를 사용하는 파드 설정 파일 예시가 있다.
myweb-rs-nn.yml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myweb-rs-nn
spec:
replicas: 3
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
nodeName: node2
containers:
- name: myweb
image: ghcr.io/c1t1d0s7/go-myweb
nodeSelector
nodeSelector 는 가장 간단하고 권장되는 노드 선택 제약 조건의 형태이다. nodeSelector 는 PodSpec의 필드이다. 이는 키-값 쌍의 매핑으로 지정한다. 파드가 노드에서 동작할 수 있으려면, 노드는 키-값의 쌍으로 표시되는 레이블을 각자 가지고 있어야 한다(이는 추가 레이블을 가지고 있을 수 있다). 일반적으로 하나의 키-값 쌍이 사용된다.
0 단계: 사전 준비
이 예시는 쿠버네티스 파드에 대한 기본적인 이해를 하고 있고 쿠버네티스 클러스터가 설정되어 있다고 가정한다.
1 단계: 노드에 레이블 붙이기
kubectl get nodes 를 실행해서 클러스터 노드 이름을 가져온다. 이 중에 레이블을 추가하기 원하는 것 하나를 선택한 다음에 kubectl label nodes <노드 이름> <레이블 키>=<레이블 값> 을 실행해서 선택한 노드에 레이블을 추가한다. 예를 들어 노드의 이름이 'kubernetes-foo-node-1.c.a-robinson.internal' 이고, 원하는 레이블이 'disktype=ssd' 라면, kubectl label nodes kubernetes-foo-node-1.c.a-robinson.internal disktype=ssd 를 실행한다.
kubectl get nodes --show-labels 를 다시 실행해서 노드가 현재 가진 레이블을 확인하여, 이 작업을 검증할 수 있다. 또한 kubectl describe node "노드 이름" 을 사용해서 노드에 주어진 레이블의 전체 목록을 확인할 수 있다.
2 단계: 파드 설정에 nodeSelector 필드 추가하기
실행하고자 하는 파드의 설정 파일을 가져오고, 이처럼 nodeSelector 섹션을 추가한다. 예를 들어 이것이 파드 설정이라면,
kubectl get nodes --show-labels
kubectl label nodes k8s-node1 gpu=highend
kubectl label nodes k8s-node2 gpu=lowend
kubectl label nodes k8s-node3 gpu=lowend
kubectl get nodes -L gpu
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myweb-rs-ns
spec:
replicas: 3
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
nodeSelector:
gpu: lowend
containers:
- name: myweb
image: ghcr.io/c1t1d0s7/go-myweb
kubectl get po -o wide
Affinity(선호도)
참조: https://waspro.tistory.com/582
- affinity
- pod
- node
- anti-affinity
- pod
affinity는 뜻 그대로 유연한 Scheduling이 가능하도록 구성할 수 있다.
앞서 살펴본 nodeSelector의 경우 label naming을 기준으로 Pod를 특정 노드 또는 특정 노드 그룹에 배포하는 방식을 사용하였다면, affinity는 다양한 조건을 제시할 수 있고 유연하게 처리할 수 있다.
affinity는 크게 노드를 기준으로 하는 node affinity와 pod 레벨에서 label을 관리할 수 있는 pod affinity으로 구분할 수 있다.
node affinity가 node level에서 배치를 관리하는다는점에서 nodeSelector와는 비슷하지만 다양한 조건을 명시할 수 있다는 유연성에서 차이가 있다.
node affinity는 크게 아래와 같이 4가지로 분류할 수 있다.
- requiredDuringSchedulingIgnoredDuringExecution
- preferredDuringSchedulingIgnoredDuringExecution
- requiredDuringSchedulingRequiredDuringExecution
- preferredDuringSchedulingRequiredDuringExecution
서두의 빨간색 required(hard affinity) & preferred(soft affinity)는 반드시 포함해야 하는지 또는 우선시하되 필수는 아닌지를 결정하는 조건이며, 중간의 파란색 Ignored & Required는 운영 중(Runtime) Node의 Label이 변경되면 무시할 것인지(Ignore) 또는 즉시 Eviction 처리(Required)하여 재기동을 수행할 것인지를 결정한다.
여기에 노드 어피니티를 사용하는 파드 예시가 있다.
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/e2e-az-name
operator: In
values:
- e2e-az1
- e2e-az2
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: another-node-label-key
operator: In
values:
- another-node-label-value
containers:
- name: with-node-affinity
image: k8s.gcr.io/pause:2.0
requiredDuringSchedulingIgnoredDuringExecution의 경우 아래 요구조건이 일치하는 node에 적용하겠다는 의미로 matchExpressions로 정의 된 key 값이 label의 [key], values 값이 label의 [value]와 일치해야 한다.
여기서 처음 정의되는 operator라는 항목이 있는데 nodeAffinity에서 사용할 수 있는 operator에는 In 외에도 NotIn, Exists, DoesNotExist, Gt, Lt 등을 활용할 수 있다.
Pod Affinity
pod affinity는 node affinity가 node의 label을 기준으로 기동했던것 처럼 pod의 label을 기준으로 조건을 만족할 경우 pod를 기동하는 방식으로 작성된다.
노드가 3개 있다. RS, STS 이 있다.
RS 에는 Web Pod 3개가 있다. STS 에는 DB Pod 가 3개 있다.
베스트 시나리오는 각각의 노드에 Web, DB 파드가 한 쌍 씩 있어야 한다.
최악의 시나리오는 노드 하나에 모든 Web Pod 가 있고 다른 노드에 DB Pod 가 나눠져서 존재하는 것이다.
베스트 시나리오 처럼 만들기 위해 Pod 와 Pod 간에 선호도를 설정해줘야 한다. 이 때 Pod Affinity 를 사용한다.
물론 최악의 시나리오로 하나의 노드에 모든 파드들이 몰려있을 수 있다. 이를 방지하기 위해 Pod anti-affinity 를 사용해야 한다. RS, STS 에서 레플리카로 Pod 가 생성되기 때문에 RS, STS 에 anti-affinity 를 적용하여 서로 같은 파드들은 배척하도록 하여 다른 노드에 배치되도록 해야 한다.
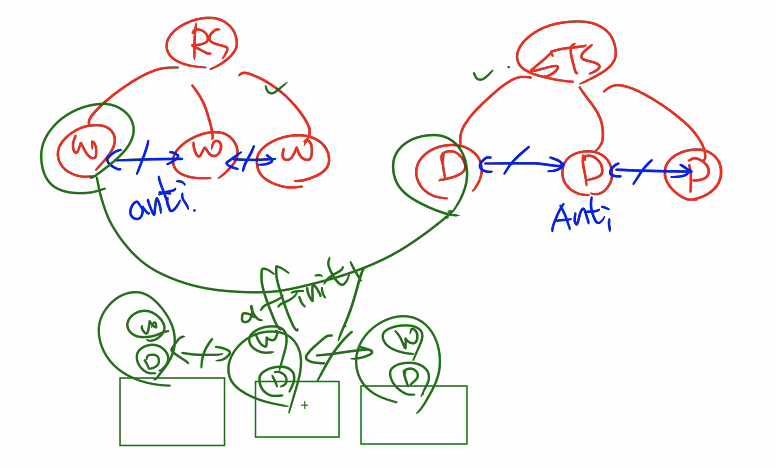
그래서 위와 같이 만들어지도록 시나리오를 작성해야 한다.
topologyKey: Pod 간에 같이 있어도 되는지, 같이 있으면 안되는지에 대한 기준이다. 즉 어떤 노드에 파드들을 어떻게 배치할지에 대해 설정한다.
myweb-rs-a.yml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myweb-a
spec:
replicas: 3
selector:
matchLabels:
app: a
template:
metadata:
labels:
app: a
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 10
preference:
matchExpressions:
- key: gpu
operator: Exists
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app: a
topologyKey: kubernetes.io/hostname
containers:
- name: myweb
image: nginx
myweb-rs-b.yml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myweb-b
spec:
replicas: 2
selector:
matchLabels:
app: b
template:
metadata:
labels:
app: b
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 10
preference:
matchExpressions:
- key: gpu
operator: Exists
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app: b
topologyKey: "kubernetes.io/hostname"
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app: a
topologyKey: "kubernetes.io/hostname"
containers:
- name: myweb
image: ghcr.io/c1t1d0s7/go-myweb
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app: a
topologyKey: "kubernetes.io/hostname"
labelSelector에 의해 pod의 라벨 정보가 app=a 인 pods가 기동 된 노드를 찾습니다.
topologyKey에 정의 된 key 값인 kubernetes.io/hostname의 value가 같은 모든 노드에 Pod를 배치한다. 이때 hostname은 모든 서버가 서로 다르므로 app=a 인 파드가 배포된 노드에만 배포가 가능하다는 결론이 나온다.
Cordon & Drain
Cordon
스케줄링 금지
kubectl cordon <노드_이름>
스케줄링 허용
kubectl uncordon <노드_이름>
drain: 노드의 Pod 들을 삭제 후 해당 노드 cordon. 데몬셋이 셋팅되어 있을 경우 ignore 옵션을 사용해야 한다. 주로 패치, 커널 업데이트를 할 때 사용한다.
kubectl drain <노드_이름>
kubectl drain <노드_이름> --ignore-daemonsets
kubectl uncordon <노드_이름>
Taint & Toleration
공식 문서: https://kubernetes.io/ko/docs/concepts/scheduling-eviction/taint-and-toleration/
Control Plane
Taint: “node-role.kubernetes.io/master:NoSchedule” → key:value == master:NoSchedule, 키밸류 형태로 master 에 스케줄링을 하지 않도록 설정한다.
Taint: 특정 노드에 역할을 부여
Toleration: Taint 노드에 스케줄링 허용
command 를 사용하여 Taint 걸기
kubectl taint node k8s-node1 node-role.kubernetes.io/master:NoSchedule
command 를 사용하여 Taint 해제
kubectl taint node k8s-node1 node-role.kubernetes.io/master:NoSchedule-
myweb-a.yml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myweb-a
spec:
replicas: 3
selector:
matchLabels:
app: a
template:
metadata:
labels:
app: a
spec:
tolerations:
- key: "node-role.kubernetes.io/masters"
operator: "Exists"
effect: "NoSchedule"
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 10
preference:
matchExpressions:
- key: gpu
operator: Exists
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app: a
topologyKey: kubernetes.io/hostname
containers:
- name: myweb
image: nginxtoleration 을 사용하여 taint 된 노드에 스케줄링을 할 수 있다.
kubectl describe node k8s-node1 | grep -i taint
특정 노드에 taint 를 거는 것은 역할을 부여하는 것이다.
toleration 을 사용해서 특정 파드들을 taint 에 의해 역할이 부여된 노드에 파드를 배치할 수 있다.
taint 를 만든 목적은 노드에 역할을 부여하기 위해서이다. taint 된 노드들은 반드시 toleration 을 사용해야 파드가 배치될 수 있다.
Kubeconfig
~/.kube/config
apiVersion: v1
kind: Config
preferences: {}
clusters:
- name: cluster.local
cluster:
certificate-authority-data: LS0tLS... # CA 인증서
server: https://127.0.0.1:6443 # 실제 api-sever 의 주소
- name: mycluster
cluster: # 새로운 클러스터를 여기에 추가할 수 있다.
server: https://x.x.x.x:6443
users:
- name: kubernetes-admin
user:
# 인증서와 키를 사용해서 서버에 사용자 인증을 한다.
client-certificate-data: LS0tLS1CRUdJTi... # 클라이언트 인증서
client-key-data: LS0tLS1CRU... # 클라이언트 개인키
contexts:
- name: kubernetes-admin@cluster.local
context: # 사용자와 클러스터를 연결
cluster: cluster.local
user: kubernetes-admin
# 현재 사용할 컨텍스트 결정
current-context: kubernetes-admin@cluster.localkubectl config view
kubectl config get-clusters
kubectl config get-contexts
kubectl config use-context myadmin@mycluster