

아파치 카프카는 ActiveMQ, Artemis, RabbitMQ 와 유사한 메시지 브로커이다. 그러나 카프카는 특유의 아키텍쳐를 가지고 있다.
카프카는 높은 확장성을 제공하는 클러스터로 실행되도록 설계되었다. 그리고 클러스터의 모든 카프카 인스턴스에 걸쳐 토픽을 파티션으로 분할하여 메시지를 관리한다. RabbitMQ 가 거래소와 큐를 사용해서 메시지를 처리하는 반면, 카프카는 토픽만 사용한다.
카프카의 토픽은 클러스터의 모든 브로커에 걸쳐 복제된다. 클러스터의 각 노드는 하나 이상의 토픽에대한 리더로 동작하며, 토픽 데이터를 관리하고 클러스터의 다른 노드로 데이터를 복제한다.
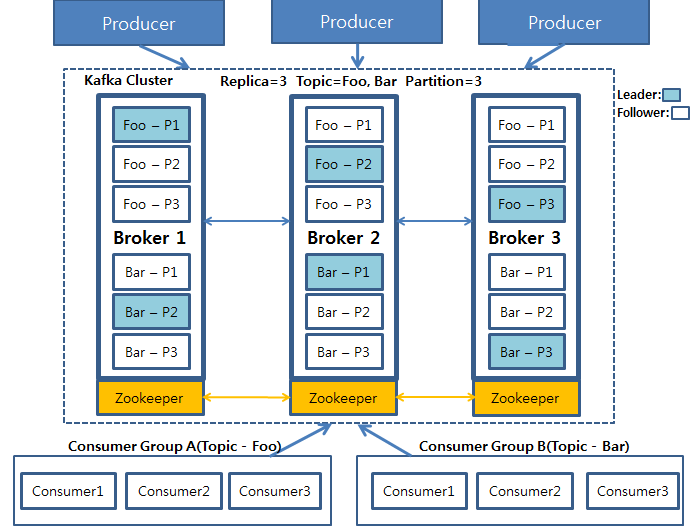
각 토픽은여러 개의 파티션으로 분할될 수 있다. 이 경우 클러스터의 각 노드는 한 토픽의 하나 이상의 파티션(토픽 전체가 아니다)의 리더가 된다.
카프카는 특유의 아키텍처를 갖고 있으므로 해당 아키텍쳐에 대해 깊게 파고들어야 한다. 여기서는 스프링을 사용하여 카프카로부터 메시지를 전송 및 수신하는 방법에 대해 초점을 둔다.
카프카 사용을 위한 스프링 설정
카프카를 사용해서 메시지를 처리하려면 이에 적합한 의존성을 빌드에 추가해야 한다. 그러나 JMS 나 RabbitMQ 와 달리 카프카는 스프링 부트 스타터가 없지만 의존성을 추가하면 된다.
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>이처럼 의존성을 추가하면 스프링 부트가 카프카 사용을 위한 자동 구성을 해준다. 이제부터 kafkaTemplate 을 주입하고 메시지를 전송, 수신하면 된다.
그러나 메시지를 전송 및 수신하기에 앞서 카프카를 사용할 때 편리한 몇 가지 속성을 알면 좋다. 특히 kafkaTemplate 은 기본적으로 localhost 에서 실행되면서 9092 포트를 리스닝하는 카프카 브로커를 사용한다. 애플리케이션을 개발할 때는 로컬의 카프카 브로커를 사용하면 좋다. 그러나 프로덕션 환경에서 사용할 때는 다른 호스트와 포트로 구성해야 한다.
spring.kafka.bootstrap-servers 속성에는 카프카 클러스터로의 초기 연결에 사용되는 하나 이상의 카프카 서버들의 위치를 설정한다. 예를 들어, 클러스터의 카프카 서버 중 하나가 kafka.test.com 에서 실행되고 9092 포트를 리스닝한다면, 이 서버의 위치를 다음과 같이 YAML 파일에 구성할 수 있다.
spring:
kafka:
bootstrap-servers:
- kafka.test.com:9092spring.kafka.bootstrap-servers 는 복수형이며, 서버 리스트를 받으므로 클러스터의 여러 서버를 지정할 수 있다.
spring:
kafka:
bootstrap-servers:
- kafka.test.com:9092
- kafka.test.com:9093
- kafka.test.com:9094이제는 프로젝트에 카프카 설정이 되었으므로 메시지를 전송, 수신할 준비가 되었다.
KafkaTemplate 을 사용해서 메시지 전송하기
KafkaTemplate 을 사용해서 Order 객체를 카프카로 전송해보자.
아래 메시지 전송 메소드를 확인해보자.
ListenableFuture<SendResult<K, V>> send(String topic, V data);
ListenableFuture<SendResult<K, V>> send(String topic, K key, V data);
ListenableFuture<SendResult<K, V>> send(String topic, Integer partition, K key, V data);
ListenableFuture<SendResult<K, V>> send(String topic, Integer partition, Long timestamp, K key, V data);
ListenableFuture<SendResult<K, V>> send(ProducerRecord<K, V> record);
ListenableFuture<SendResult<K, V>> send(Message<?> message);
ListenableFuture<SendResult<K, V>> sendDefault(V data);
ListenableFuture<SendResult<K, V>> sendDefault(K key, V data);
ListenableFuture<SendResult<K, V>> sendDefault(Integer partition, K key, V data);
ListenableFuture<SendResult<K, V>> sendDefault(Integer partition, Long timestamp, K key, V data);KafkaTemplate 은 제너릭 타입을 사용하고, 메시지를 전송할 때 직접 도메인 타입을 처리할 수 있다. 따라서 모든 send() 메소드가 컨버팅 기능을 갖고 있다고 생각하면 된다. 카프카에서 메시지를 전송할 때는 메시지가 전송되는 방법을 알려주는 다음 매개 변수를 지정할 수 있다.
- 메시지가 전송될 토픽(send() 에 필요)
- 토픽 데이터를 쓰는 파티션(optional)
- 레코드 전송 키(optional)
- 타임 스탬프(optional, 기본값은 System.currentTimeMillis())
- 페이로드(메시지에 적재된 순수한 데이터, 여기서는 Order 객체, required)
토픽과 페이로드는 가장 중요한 매개변수들이다. 파티션과 키는 send() 와 sendDefault() 에 매개변수로 제공되는 추가 정보일 뿐 KafkaTemplate 을 사용하는 방법에는 거의 영향을 주지 않는다. 여기서는 지정된 토픽에 메시지 페이로드를 전송하는 데 초점을 둘 것이다.
send() 메서드에는 ProducerRecord 를 전송하는 것이 있다. ProducerRecord 는 모든 선행 매개변수들을 하나의 객체에 담은 타입이다. 또한, Message 객체를 전송하는 send() 메소드도 있지만 이 경우 도메인 객체를 Message 객체로 변환해야 한다. 보통 ProducerRecord 나 Message 객체를 생성 및 전송하는 것보다는 다른 send() 메소드 중 하나를 사용하는 것이 더 간편하고 쉽다.
KafkaTemplate 과 send() 메소드를 사용하여 주문 데이터를 전송하기 위한 코드는 아래와 같다.
@Service
@RequiredArgsConstructor
public class KafkaOrderMessagingService implements OrderMessagingService {
private final KafkaTemplate<String, Order> kafkaTemplate;
@Override
public void sendOrder(Order order) {
kafkaTemplate.send("my.orders.topic", order);
}
}sendOrder() 메소드는 주입된 KafkaTemplate 의 send() 메소드를 사용하여 my.orders.topic 이라는 이름의 토픽으로 Order 객체를 전송한다. 만일 기본 토픽을 설정한다면 sendOrder() 메소드를 더 간단하게 만들 수 있다. 기본 토픽을 설정하는 방법은 아래처럼 YAML 파일에 정의하는 방법이다.
spring:
kafka:
template:
default-topic: my.orders.topic그 다음 sendOrder() 메소드에서 send() 대신 sendDefault() 메소드를 호출하면 된다. 이 때는 토픽 이름을 인자로 전달하지 않는다.
@Override
public void sendOrder(Order order) {
kafkaTemplate.sendDefault(order);
}카프카 리스너 작성
send() 와 sendDefault() 메소드 외에도 KafkaTemplate 은 메시지를 수신하는 메소드를 제공하지 않는다. 따라서 스프링을 사용해서 카프카 토픽의 메시지를 가져오는 유일한 방법은 메시지 리스너를 작성하는 것이다.
카프카의 경우 메시지 리스너는 @KafkaListener 어노테이션이 지정된 메소드에 정의된다. @KafkaListener 는 @JmsListener 나 @RabbitListener 와 거의 유사하며, 동일한 방법으로 사용된다. 아래 코드를 확인하자.
@Component
@RequiredArgsConstructor
public class OrderListener {
private final KitchenUI ui;
@KafkaListener(topics="my.orders.topic")
public void handle(Order order) {
ui.displayOrder(order);
}
}my.orders.topic 이라는 이름의 토픽에 메시지가 도착할 때 자동 호출되어야 한다는 것을 나타내기 위해 handle() 메소드에는 @KafkaListenr 어노테이션이 지정되었다. 그리고 페이로드인 Order 객체만 handle() 의 인자로 받는다. 그러나 메시지의 추가적인 메타데이터가 필요하다면 ConsumerRecord 나 Message 객체도 인자로 받을 수 있다.
다음의 handle() 메서드에는 수신된 메시지의 파티션과 타임스탬프를 로깅하기 위해 ConsumerRecord 를 인자로 받는다.
@KafkaListener(topics="my.orders.topic")
public void handle(Order order, ConsumerRecord<Order> record) {
log.info("Received from partition {} with timestamp {}", record.partition(), record.timestamp());
ui.displayOrder(order);
}이와 유사하게 ConsumerRecord 대신 Message 객체를 요청하여 같은 일을 처리할 수 있다.
@KafkaListener(topics="my.orders.topic")
public void handle(Order order, Message<Order> message) {
MessageHeaders headers = message.getHeaders();
log.info("Received from partition {} with timestamp {}", headers.get(KafkaHeaders.RECEIVED_PARTITION_ID), headers.get(KafkaHeaders.RECEIVED_TIMESTAMP));
ui.displayOrder(order);
}메시지 페이로드는 ConsumerRecord.value() 나 Message.getPayload() 를 사용해도 받을 수 있다. handle() 의 매개변수로 직접 Order 객체를 요청하는 대신 ConsumerRecord 나 Message 객체를 통해 Order 객체를 요청할 수 있다.